timestamp格式也无法匹配一致,换成varchar类型之后就可以匹配了,但是汉字不知道如何解决,JDBC连接加上了useunicode=true&characterEncoding=utf-8还是没有效果

这个能具体一点吗? sql server的表和mysql的表结构给一下,我们来试一下. 给几个你测试不行的字段就成.
#源表结构 CREATE TABLE [dbo].[PFXHD] ( [DJBH] varchar(20) COLLATE Chinese_PRC_CI_AS NOT NULL, [RQ] datetime NULL, [DM1] varchar(20) COLLATE Chinese_PRC_CI_AS NULL, [QDDM] varchar(20) COLLATE Chinese_PRC_CI_AS NULL, )
CREATE TABLE [dbo].[PFXHDMX] ( [DJBH] varchar(20) COLLATE Chinese_PRC_CI_AS NOT NULL, [MXBH] int IDENTITY(1,1) NOT NULL, [SPDM] varchar(20) COLLATE Chinese_PRC_CI_AS NULL, [GG1DM] varchar(20) COLLATE Chinese_PRC_CI_AS NULL, [GG2DM] varchar(20) COLLATE Chinese_PRC_CI_AS NULL, [SL] numeric(18,4) NULL, [DJ] numeric(18,4) NULL, [BZJE] numeric(18,4) NULL, )
#表输入SQL SELECT T1.DJBH,CONVERT(varchar(100), T1.RQ,120) AS RQ,T1.DM1 AS KHDM,T1.QDDM,T2.MXBH,T2.SPDM,T2.GG1DM,T2.GG2DM,T2.SL,T2.DJ,T2.BZJE FROM PFXHD T1 left JOIN PFXHDMX T2 ON T2.DJBH=T1.DJBH
#目标表结构
CREATE TABLE test (
MXBH int NOT NULL,
djbh varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT '' COMMENT '单据编号',
rq varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT '' COMMENT '日期',
khdm varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT '' COMMENT '客户ID',
qddm varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT '' COMMENT '渠道ID',
SPDM varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT '',
GG1DM varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT '',
GG2DM varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT '',
SL decimal(18, 4) NULL DEFAULT NULL,
DJ decimal(18, 4) NULL DEFAULT NULL,
BZJE decimal(18, 4) NULL DEFAULT NULL,
PRIMARY KEY (MXBH) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- Records of test
INSERT INTO test VALUES (27754, 'FA300005884', '2022-04-15 00:00:00', '9018', '000', 'HD4005鞋垫', 'GRAY', '235', 1.0000, 0.0000, 0.0000);
好,我先试一下
你提供的是mysql的示例数据,你应该是从sql server到mysql吧? 要提供一条sql server的示例数据
数据是一样的额,MYSQL数据就是我全量同步过去的,两张表都用这条数据测就行了 两张表实际都已经存在这条数据了,每次匹配FLAG都是'U',如果我勾上其他含有中文的字段匹配,就会出现更多U
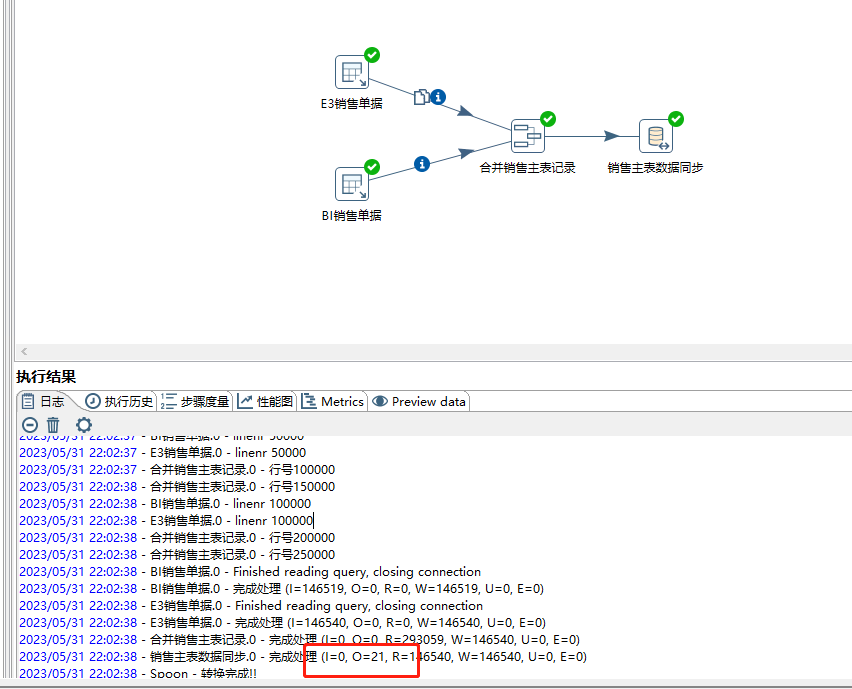
{"debugLevel":"1","processId":"647608e6b9ff37402f145591","transactionId":"6477030d1e7eb31db49c9e44","singleStep":"false","pageNo":1,"dataSourceId":"ETL_SQLSERVER_230530001","tableName":"","nodeId":"T00001","state":true,"total":1,"P_ENDFLAG":"1","P_PREV_NODEID":"T00005","data":[{"DJBH":"FA300005884","RQ":"2022-04-15 00:00:00","KHDM":"9018","QDDM":"000","MXBH":27754,"SPDM":"HD4005鞋垫","GG1DM":"GRAY","GG2DM":"235","SL":"1.0000","DJ":"0.0000","BZJE":"0.0000","P_TAG_IUD":"U"}]
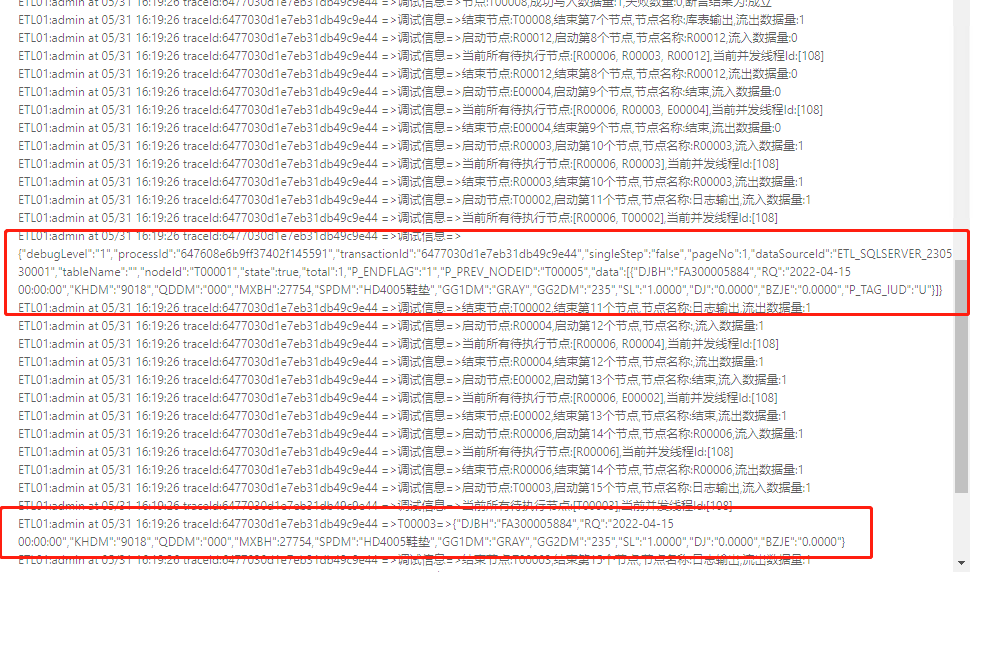
你是用cdc实现增量的还是说用的ETL的离线实现增量的?
从mssql同步到mysql里面都正常啊
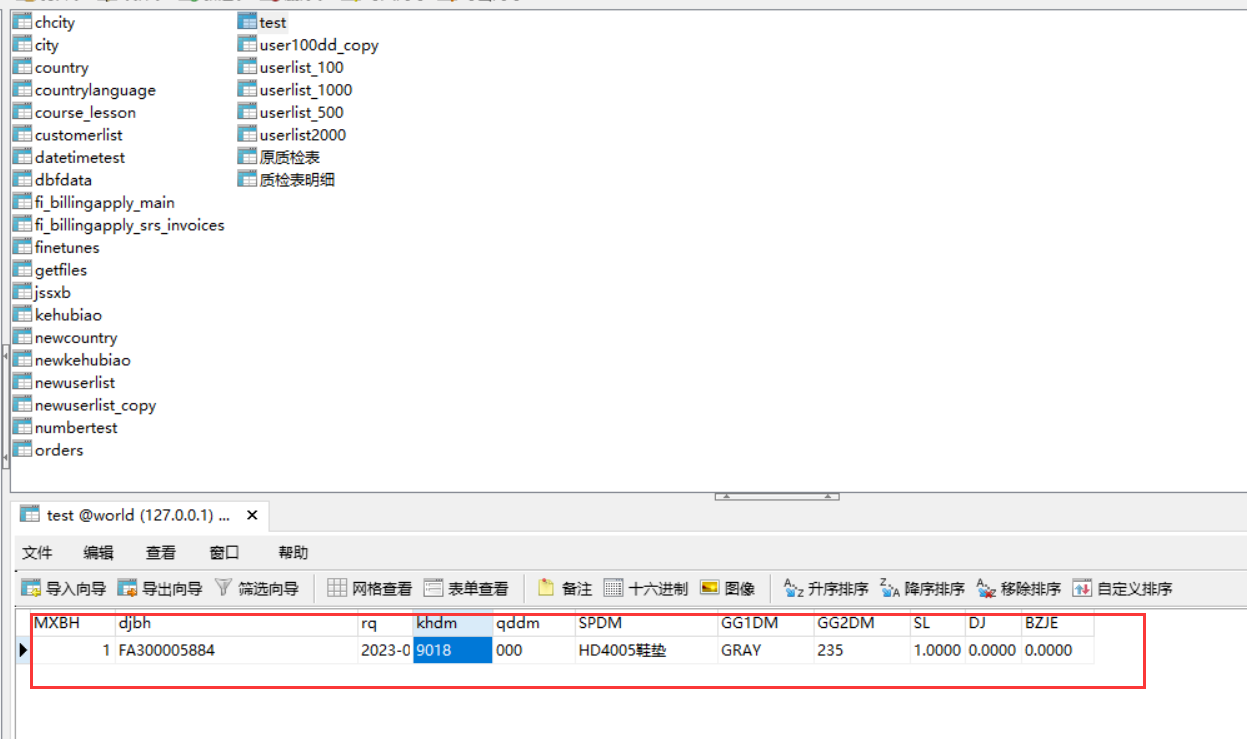
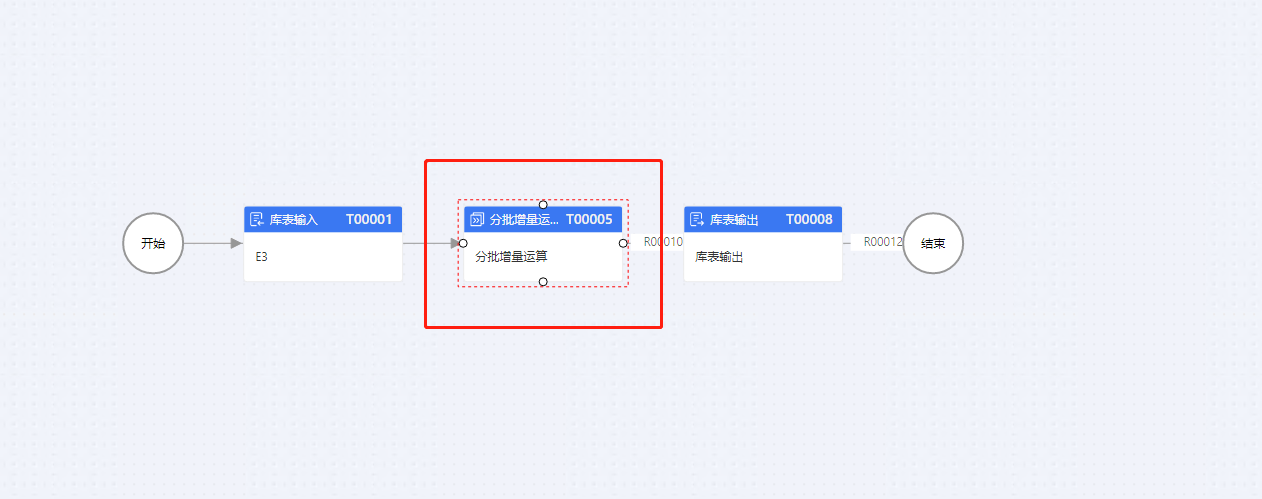
 是离线分批增量运算额
是离线分批增量运算额
中间这步增量运算,如果有中文字符,对比出来的'P_TAG_IU'一直是'U'
我先测试一下
经过测试是因为你有三个数字类型的字段,在两边进行比较时因为精度不一样所以计算为更新了,这个问题在下一个版本会进行修复.
#谢谢!我刚才也测了一下,数字计算确实也会出现类似问题,
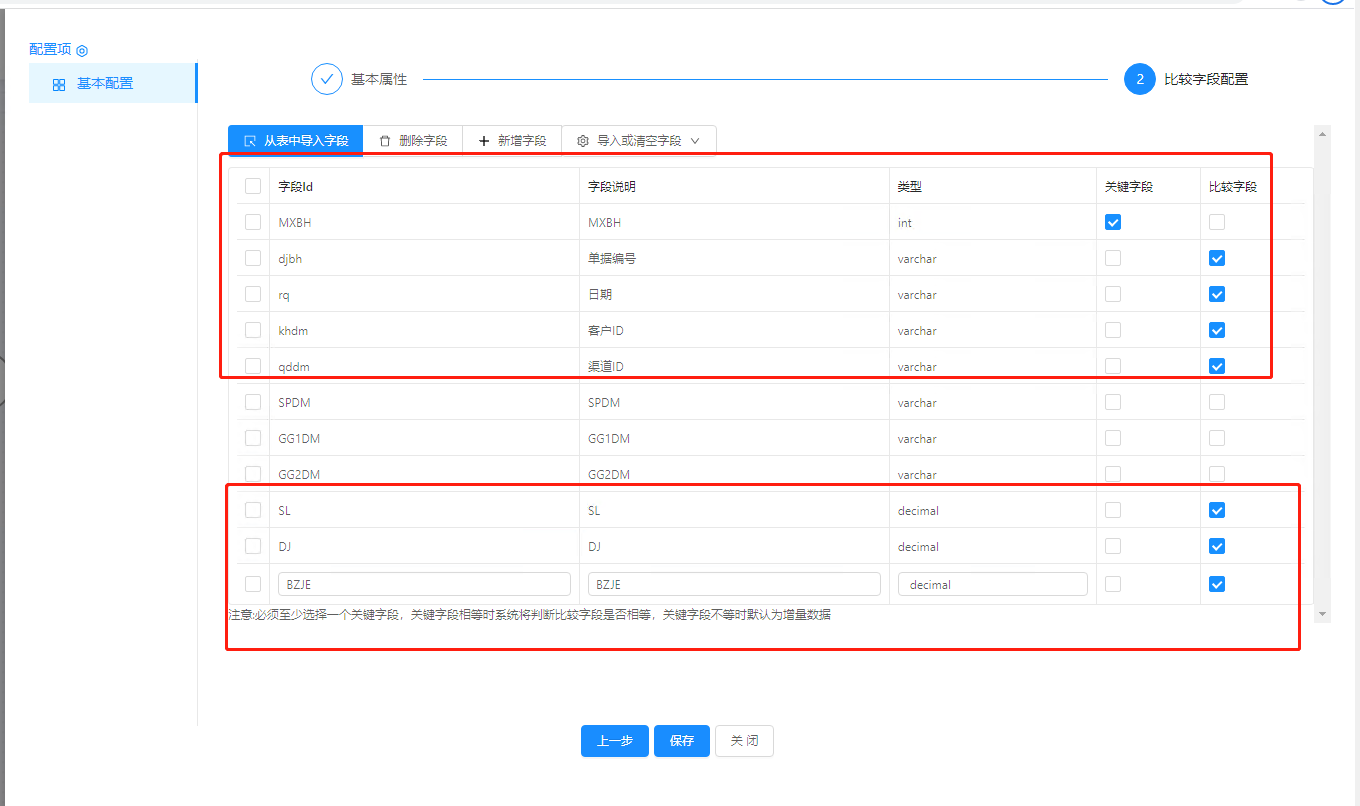
 #但是当我不选中数字类型的字段,勾选SPDM字段之后还是会出现这种情况,不知道是不是我其他地方设置问题
#但是当我不选中数字类型的字段,勾选SPDM字段之后还是会出现这种情况,不知道是不是我其他地方设置问题
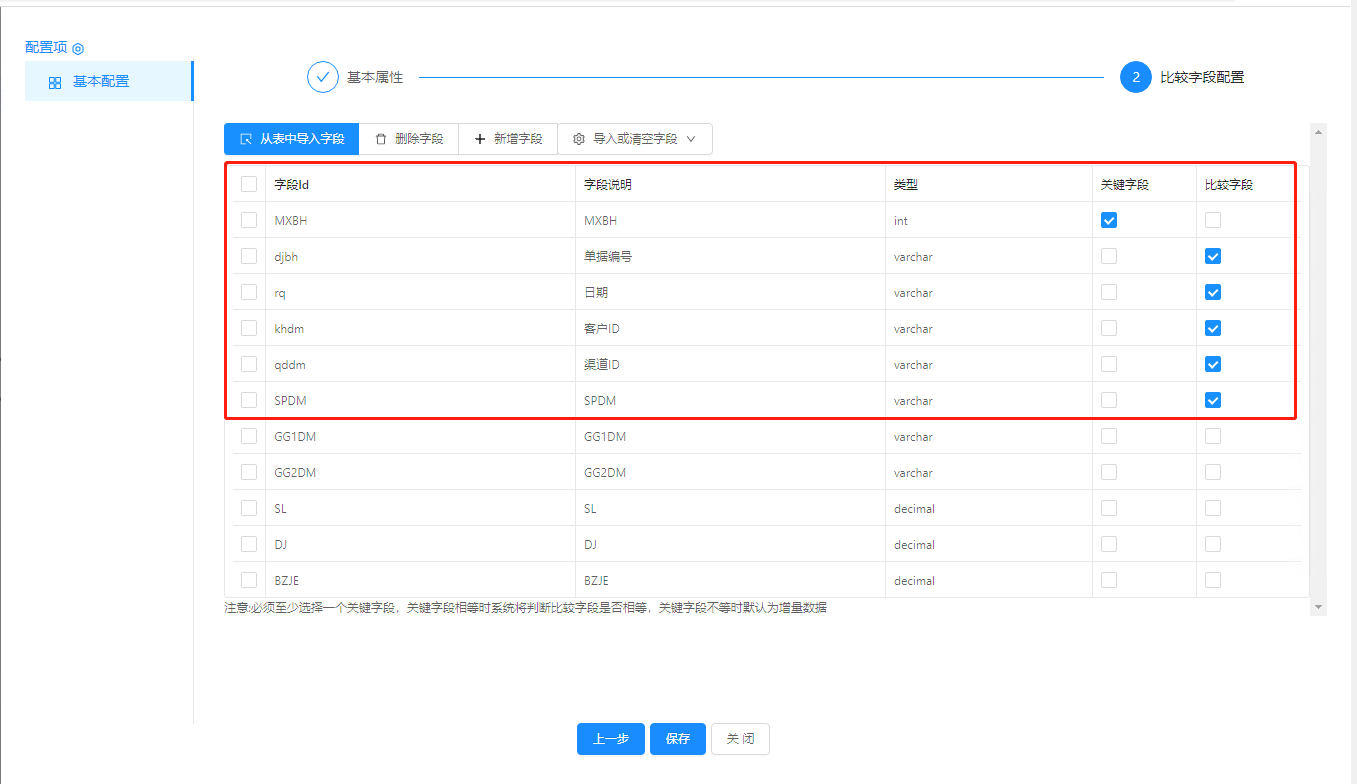
 #最后我不勾选包含汉字的字段和数字类型字段时,就正常了
#最后我不勾选包含汉字的字段和数字类型字段时,就正常了
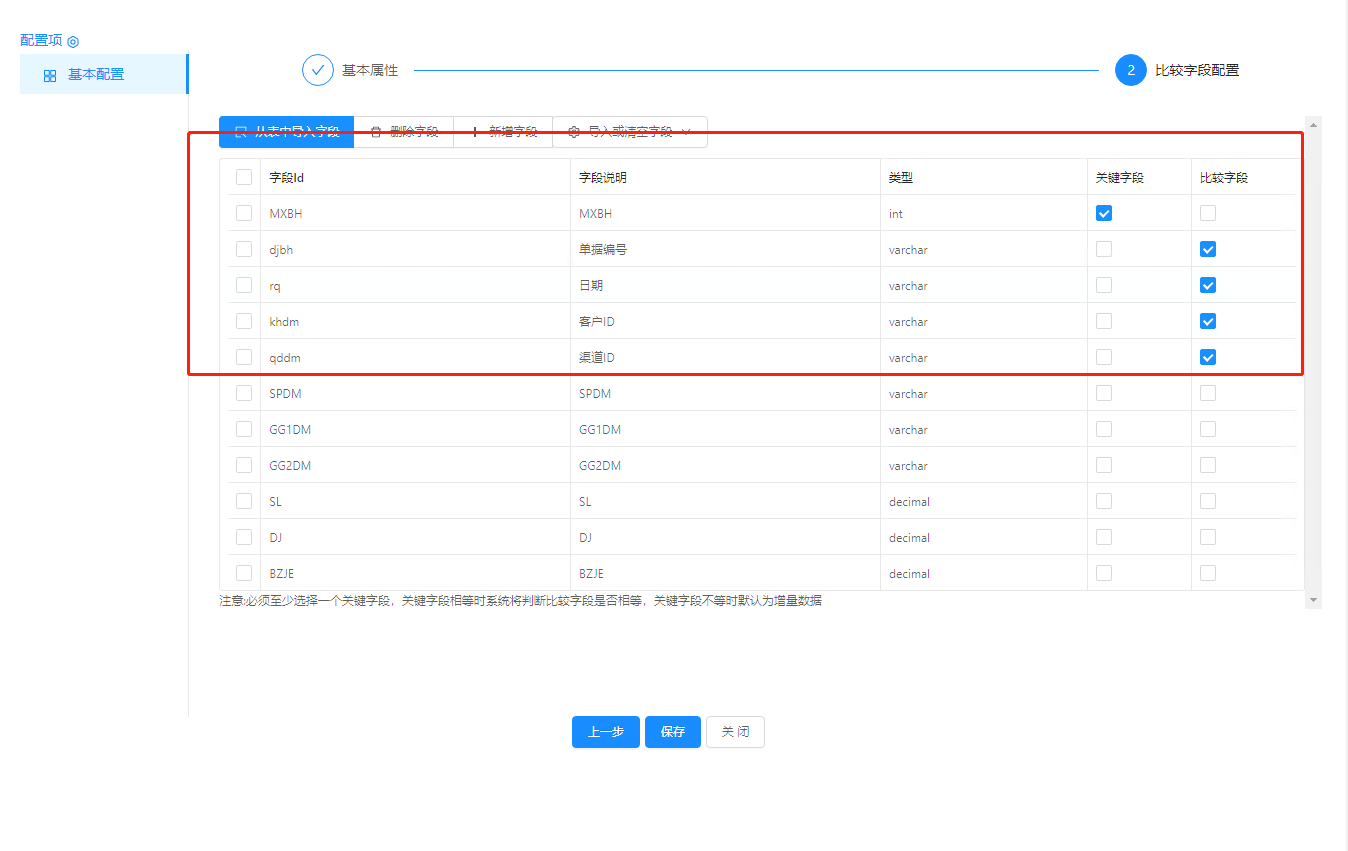
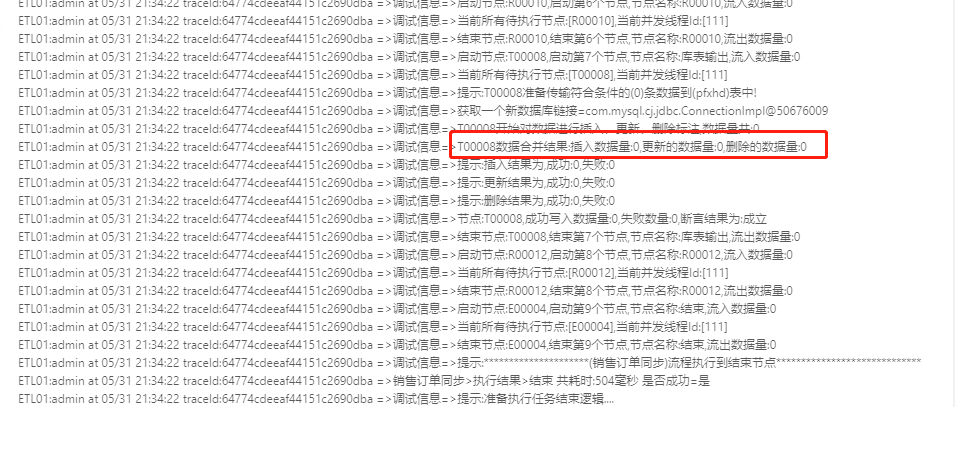 #所以我目前的环境应该数字和汉字都会出现这种情况- -,请问您那边有针对中文字符做其他配置吗?
#所以我目前的环境应该数字和汉字都会出现这种情况- -,请问您那边有针对中文字符做其他配置吗?
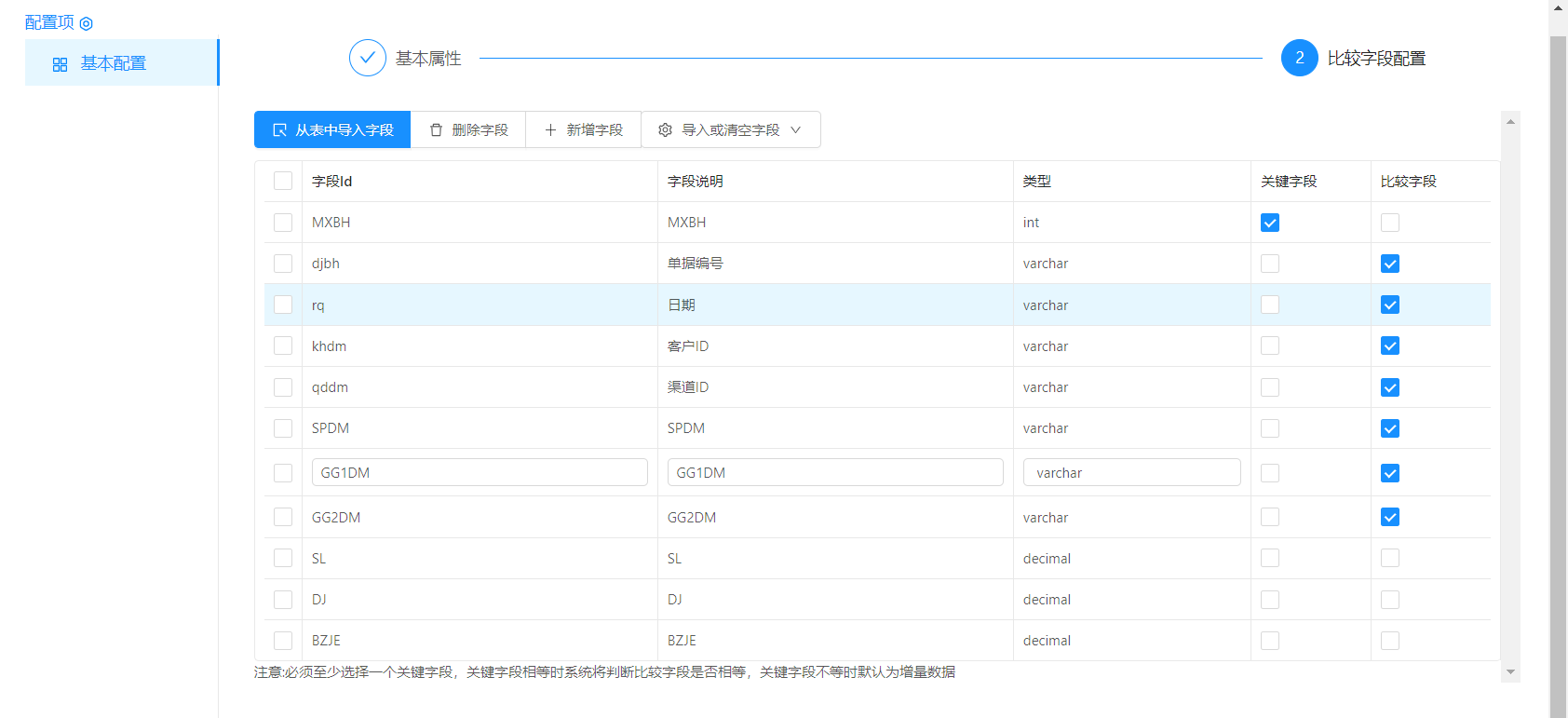 我这里只要不选数字就可以了,中文没有发现有问题.
我这里只要不选数字就可以了,中文没有发现有问题.
好吧,可能还是环境兼容性有点不同,我这两张表在kettle同步都能过,下次更新timestamp类型精度兼容性也可以考虑优化一下,kettle这两个字段比较可以过
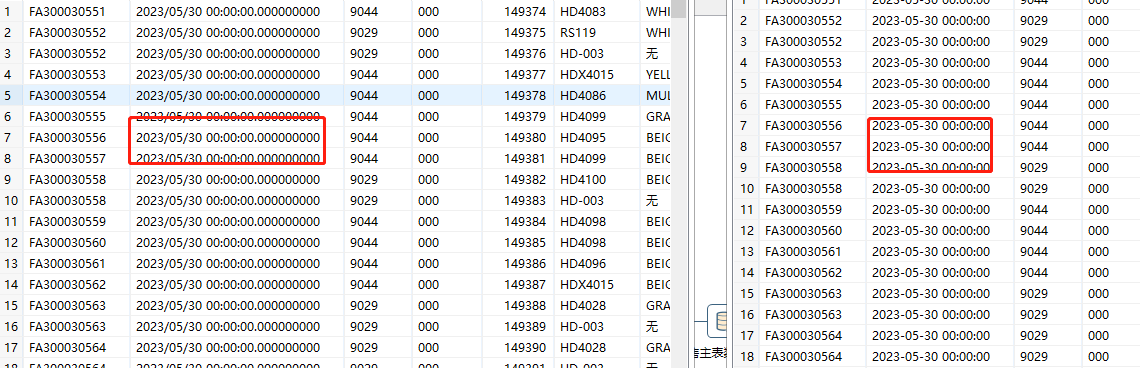
这个差异从前端能调试出来吗?我用相同sql语句在kettle把这两张表又测了一遍,1秒就过了,这个问题研究一天了- -,强迫症都要犯了0-0